12 Content-Based Recommender System
12.1 Architettura di un Content Based Recommender System
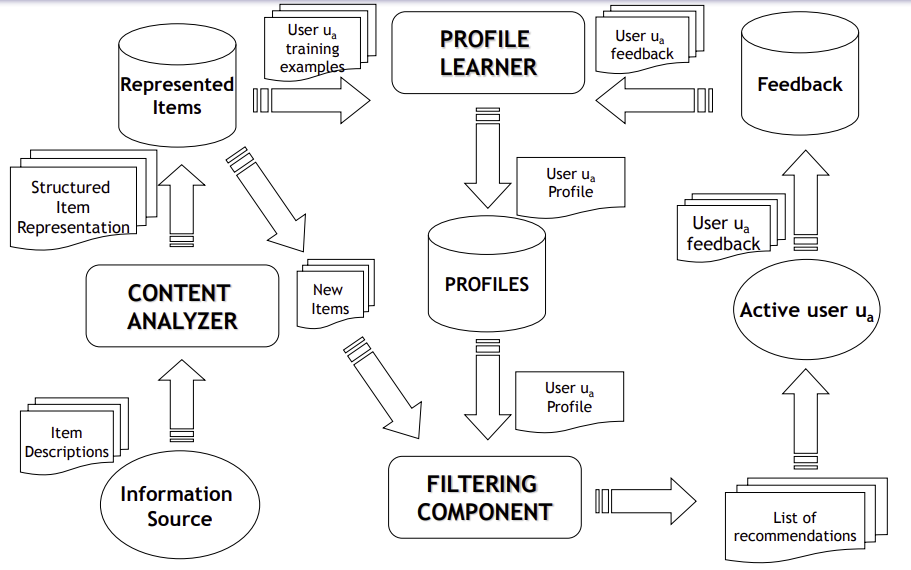
Il processo di raccomandazione viene eseguito in tre fasi, ognuna delle quali è gestita da un componente separato:
Content Analyzer: quando le informazioni non hanno una struttura, è necessario un passo di pre-elaborazione per estrarre informazioni strutturate rilevanti. Lo scopo di questo componente è rappresentare il contenuto degli elementi provenienti da varie fonti in una forma adatta all’elaborazione. Gli elementi dati vengono analizzati mediante tecniche di estrazione delle feature al fine di rappresentare l’informazione mediante feature (parole chiave, n-gram, concetti, …), e vengono memorizzati nel repository “Represented Items”. Questa rappresentazione è l’input per il Profile Learner e il Filtering Component
Profile Learner: questo modulo raccoglie dati rappresentativi delle preferenze dell’utente dal repository “Feedback” e cerca di costruire il profilo dell’utente. Di solito, la strategia di generalizzazione è realizzata mediante tecniche di apprendimento automatico, in grado di dedurre un modello degli interessi dell’utente a partire dagli elementi piaciuti o non piaciuti in passato, oppure in modo esplicito dall’utente, che esplicita le sue aree di interesse senza fornire dei feedback
Filtering Component: questo modulo sfrutta il profilo utente per suggerire elementi rilevanti confrontando la rappresentazione del profilo con quella degli elementi da raccomandare. Il risultato è un giudizio di rilevanza binario o continuo (calcolato mediante misure di similarità), nel secondo caso si ottiene una lista ordinata di elementi potenzialmente interessanti.
12.2 Pro
L’adozione dei content-based recommender system presenta diversi vantaggi rispetto a quello collaborativo:
• Indipendenza dall’utente: i CBRS sfruttano esclusivamente le valutazioni fornite dall’utente attivo per costruire il suo profilo. Al contrario, i collaborative-based RS necessitano di valutazioni da parte di altri utenti per trovare i vicini dell’utente attivo, ovvero utenti con gusti simili poiché hanno valutato gli stessi elementi in modo simile.
• Trasparenza: le spiegazioni su come funziona il sistema di raccomandazione possono essere fornite elencando esplicitamente le caratteristiche del contenuto o le descrizioni che hanno causato l’inclusione di un elemento nell’elenco delle raccomandazioni. Al contrario, i sistemi collaborativi sono scatole nere poiché l’unica spiegazione per una raccomandazione di un elemento è che utenti sconosciuti con gusti simili hanno apprezzato quell’elemento.
• New item: i CBRS sono in grado di consigliare elementi non ancora valutati da nessun utente. Di conseguenza, non soffrono del problema del “new-item”, che colpisce i sistemi collaborativi, in cui se il nuovo elemento non viene valutato da un numero sostanziale di utenti, il sistema non sarà in grado di raccomandarlo.
12.3 Contro
Tuttavia, i sistemi basati sul contenuto presentano diverse limitazioni:
• Limited Content Analysis: Nessun CBRS può fornire suggerimenti adeguati se il contenuto analizzato non contiene informazioni sufficienti per discriminare gli elementi che piacciono all’utente da quelli che non piacciono. Alcune rappresentazioni catturano solo determinati aspetti del contenuto, ma ce ne sono molti altri che influenzerebbero l’esperienza dell’utente. Spesso è necessaria la conoscenza del dominio e talvolta sono necessarie delle ontologie.
• More of the same/Overspecialization: i CBRS non hanno un metodo intrinseco per trovare qualcosa di inaspettato. Il sistema suggerisce elementi il cui punteggio è alto quando confrontato con il profilo dell’utente, quindi l’utente riceverà raccomandazioni simili agli item già valutati. Questo inconveniente è chiamato anche problema della serendipità per evidenziare la tendenza dei sistemi basati sul contenuto a produrre raccomandazioni con un grado limitato di novità. Ad esempio, se un utente ha valutato positivamente solo film di Harry Potter, gli verranno raccomandati solo film di quel tipo. Alcune soluzioni: - Limitare superiormente il livello di similarità in modo da eliminare gli item con un livello eccessivo di similarità. - Introdurre casualità nel sistema, ad esempio offrendo su 5 suggerimenti 1 scelto in modo casuale, non sulla base del profilo dell’utente. - Introdurre conoscenza esterna nel sistema arricchendo la descrizione degli elementi con features che permettono di mettere in relazione gli elementi in modo inedito e inaspettato.
• New User: devono essere raccolte abbastanza valutazioni prima che un CBRS possa davvero capire le preferenze dell’utente e fornire raccomandazioni accurate. Pertanto, quando ci sono poche valutazioni disponibili, come nel caso di un nuovo utente, il sistema non sarà in grado di fornire raccomandazioni affidabili.